Requirements for the HyperScope Stage One (V1)
Writing a Requirements Document for a worthwhile and ambitious project is an incredible journey. From flashes of insight to fogs of confusion and throughs in tornados there are only rare glimpses of calm sun-shine.
A major problem in writing the Requirements Document for HyperScope has been the richness, the depth and the scope of Doug Engelbarts vision. It's been further comlicated and hepled, in equal parts, by the fact that he has done most of this before, so we do not need to really worry about whether this technically impressive system is actually do-able. It is done. It lives in Augment. New complications arise from the integration into the real world of today. And that is certainly something which can be tackled
But the other major problem, whcih I previously attributed to my lazyness, was the issue of structure. I just got of the phone with Doug here in Palo Alto. We have had a bit of a tough time dealing with eachother lately. On the phone, going through issues of how to integrate other works, such as argument mapping, it struck me: I will write it all out in terms of how the information flows into and through the system,, pmappign out requirements as we get to them. This will also be a good eway to emphasize an early and major requirement, that of keeping the various components as separate as possible, only allowing them to communicate through clearly defined, public methods (APIs). As with most journeys, the HyperScope's information journey begins in the real world.
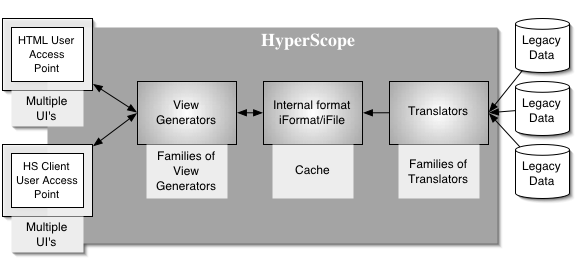
![]() The real world
: Legacy Data
The real world
: Legacy Data
This is where the legacy data lives. In plain vanilla HTML files, in HTML files with JavaScipt and CSS, Java Applets and XML. Data lives in Word documents, Excel spreadhseets and in emails. There are databases and there are many, many different file formats. It is a complicated scenario. But it is just the way it is.
By the way, legacy data is defined simply as data somwhere outside the HyperScope which may or may not be accessible, but which the HyperScope user cannot change and save over the original.
![]() Translators/Transcoders
Translators/Transcoders
In order for the HyperScope to be able to access and augment this legacy data, it has to be translated into the internal format for Hyperscope.
We need to choose which formats to support the importof initially and these are plain HTML and others which are to be decided as we learn more about the initial user community (to be decided as well).
Initial Legacy Formats Supported:
- Plain HTML.
- Further formats as decided by the initial user community.
Translator Requirements:
- Translator Version Control. As a document is translated into the HyperScope, the translation needs to record which version of the translator was used in order to make sure the same view of that file will be shown in the future, even if the translator improves.
 Internal File
Format/iFile
Internal File
Format/iFile
The internal file format, often refered to as iFile (though it does not necessarily have to be in a file, it could be in a database etc.) will have to support several propperties:
iFile Properties will have to include:
- Augment propperties.
- HTML propperties.
 View Generators
View Generators
The View Generators provide the user with powerful ways to see the documents. It is not decided at this point where the View Generators will reside; on the server or in the client.
View Generator Functional Requirements:
- X
View Generator Attribute Requirements:
- Must allow for fast changes.
 HyperScope Client
User Access Point
HyperScope Client
User Access Point
This is where the rubber meets the road, or rather, the user gets to interact with the documents.
Client User Access Point Functional Requirements:
- X
Client User Access Point Attribute Requirements:
- Must allow for fast changes.
 HTML User Access
Point
HTML User Access
Point
In addition to the actual HyperScope client, users will be able to access some of the features of the HyperScope served up to browsers as standard HTML (which may be JavaScript enhanced).
HTML User Access Point Functional Requirements:
- X
HTML User Access Point Attribute Requirements:
- Must allow for fast changes.